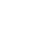mysql 第35章 索引的原理,B+树、聚集索引和二级索引的结构分析
mysql 第35章 索引的原理,B+树、聚集索引和二级索引的结构分析
一、什么是索引
索引是一种用于快速查询行的数据结构,就像一本书的目录就是一个索引,如果想在一本书中找到某个主题,一般会先找到对应页码。
在 mysql 中,存储引擎用类似的方法使用索引,先在索引中找到对应值,然后根据匹配的索引记录找到对应的行。
二、B树索引
大多数存储引擎都支持 B 树索引。
B 树通常意味着所有的值都是按顺序存储的,并且每一个叶子也到根的距离相同。
B 树索引能够加快访问数据的速度,因为存储引擎不再需要进行全表扫描来获取数据。
下图就是一颗简单的 B 数。
B 树的查询流程:
如上图我要从找到E字母,查找流程如下:
获取根节点的关键字进行比较,当前根节点关键字为 M,E
拿到关键字 D 和 G,D
拿到 E 和 F,因为 E=E 所以直接返回关键字和指针信息(如果树结构里面没有包含所要查找的节点则返回 null);
通过指针信息取出这条记录的所有信息;
三、B+树索引
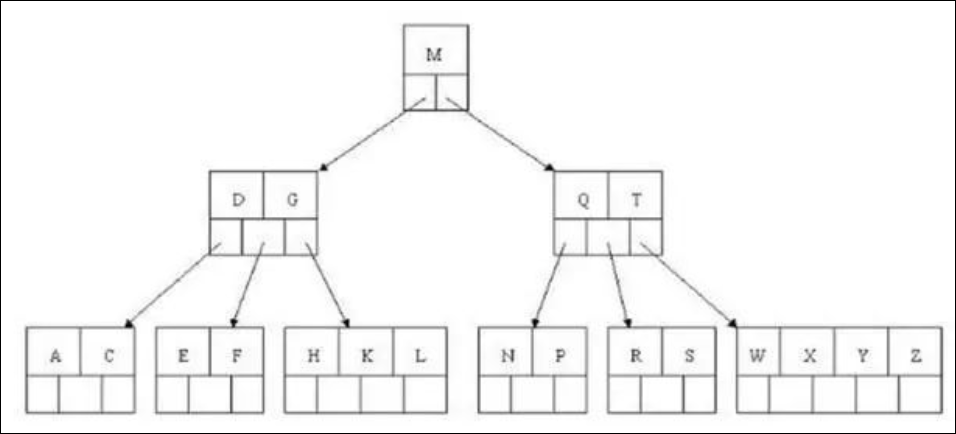
下图为 B+树的结构,B+树是B树的升级版,我们可以观察一下,B 树和 B+树的区别是什么?
B+树和 B 树的区别是:
B 树的节点中没有重复元素,B+树有。
B 树的中间节点会存储数据指针信息,而 B+树只有叶子节点才存储。
B+树的每个叶子节点有一个指针指向下一个节点,把所有的叶子节点串在了一起。
从下图我们可以直观的看到 B树和 B+树的区别:紫红色的箭头是指向被索引的数据的指针,大红色的箭头即指向下一个叶子节点的指针。
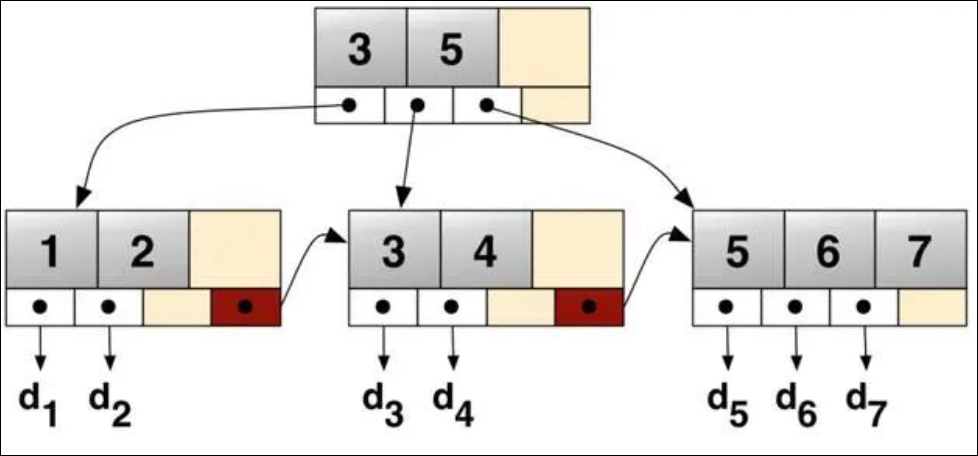
我们假设被索引的列是主键,现在查找主键为 5 的记录,模拟一下查找的过程:
B 树,在倒数第二层的节点中找到 5 后,可以立刻拿到指针获取行数据,查找停止。
B+树,在倒数第二层的节点中找到 5 后,由于中间节点不存有指针信息,则继续往下查找,在叶子节点中找到 5,拿到指针获取行数据,查找停止。
B+树每个父节点的元素都会出现在子节点中,是子节点的最大(或最小)元素。叶子节点存储了被索引列的所有的数据。
那 B+树比起 B 树有什么优点呢?
由于中间节点不存指针,同样大小的磁盘页可以容纳更多的节点元素,树的高度就小。(数据量相同的情况下,B+树比 B 树更加“矮胖”),查找起来就更快。
B+树每次查找都必须到叶子节点才能获取数据,而 B 树不一定,B 树可以在非叶子节点上获取数据。因此 B+树查找的时间更稳定。
B+树的每一个叶子节点都有指向下一个叶子节点的指针,方便范围查询和全表查询:只需要从第一个叶子节点开始顺着指针一直扫描下去即可,而 B 树则要对树做中序遍历。
了解了 B+树的结构之后,我们对一张具体的表做分析:
create table Student(
last_name varchar(50) not null,
first_name varchar(50) not null,
birthday date not null,
gender int(2) not null,
key(last_name, first_name, birthday)
);
对于表中的每一行数据,索引中包含了 name,birthday 列的值。下图显示了该索引的结构:
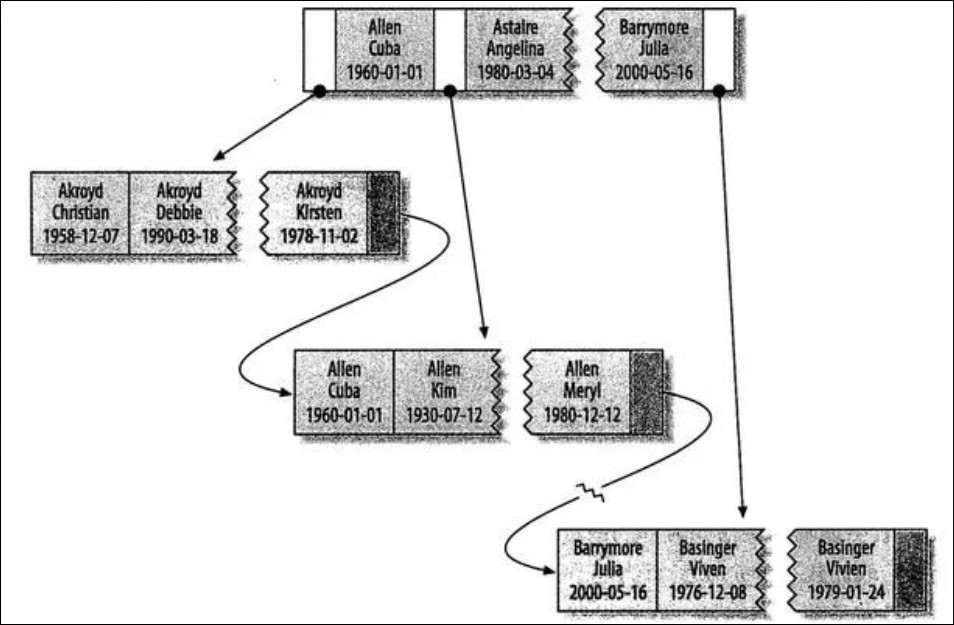
索引对多个值进行排序的依据是 create table 语句中定义索引时列的顺序,即如果名字相同,则根据生日来排序。
B+树的结构决定了这种索引对以下类型的查询有效:
全值匹配 和索引中所有的列进行匹配,例如查找姓名为 Cuba Allen,生日为 1960-01-01 的人。
匹配最左前缀 查找姓为Allen的人,即只用索引的第一列。
匹配列前缀 匹配某一列的值的开头部分,例如查找所有以 J 开头的姓的人。
匹配范围值 查找姓在 Allen 和 Barrymore 之间的人。
精确匹配某一列并范围匹配另外一列 查找姓为 Allen,名字是字母 K 开头的人。即第一列 last_name 全匹配,第二列 first_name 范围匹配。
只访问索引的查询 查询只需要访问索引,无需访问数据行。这种索引叫做覆盖索引。
一些限制:
如果不是按照索引的最左列开始查找,无法使用索引。例如上面例子中的索引无法用于查找某个特定生日的人,因为生日不是最左数据列。也不能查找 last_name 以某个字母结尾的人。
不能跳过索引的列。上述索引无法用于查找 last_name 为 Smith 并且某个特定生日的人。如果不指定 first_name,则 mysql 只能使用索引的第一列。
如果查询中有某个列的范围查询,则右边所有的列都无法使用索引优化查找。例如查询 WHERE last_name=’Smith’ AND first_name LIKE ‘J%’ AND birthday=‘1996-05-19’,这个查询只能使用索引的前两列。
四、哈希索引
哈希索引,只有精确匹配索引所有列的查询才有效。
对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码。
哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
如果多个列的哈希值相同,索引会以链表的方式存放多个指针记录到同一个哈希条目中。
因为索引自身只存储对应的哈希值,所以索引的结构十分紧凑,哈希索引查找的速度非常快。
但是哈希索引也有它的限制:
哈希索引不是按照索引顺序存储的,无法用于排序。
不支持部分索引列匹配查找。
不支持范围查找。
五、聚集索引
每个存储引擎为 InnoDB 的表都有一个特殊的索引,叫聚集索引。
聚集索引并不是一种单独的索引类型,而是一种数据存储方式。
当表有聚集索引的时候,它的数据行实际上存放在叶子页中。
一个表不可能有两个地方存放数据,所以一个表只能有一个聚集索引。
因为是存储引擎负责实现索引,因此不是所有的存储引擎都支持聚集索引。
InnoDB 表中聚集索引的索引列就是主键,所以聚集索引也叫主键索引。
例如下面这张 InnoDB 表:
create table Student(
id int(11) primary key auto_increment,
last_name varchar(50) not null,
first_name varchar(50) not null,
birthday date not null
);
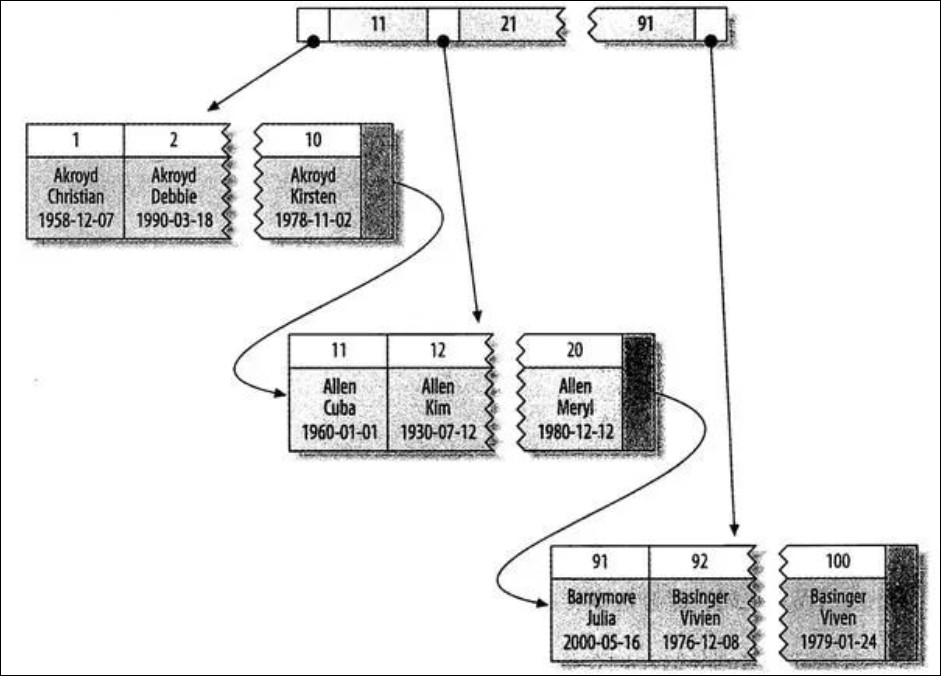
这是一课 B+树,它的叶子页包含了行的全部数据,节点页只包含了索引列(即主键)。
六、二级索引
对于 InnoDB 表,在非主键列的其他列上建的索引就是二级索引(因为聚集索引只有一个)。
二级索引可以有 0 个,1 个或者多个。
二级索引和聚集索引的区别是什么呢?二级索引的节点页和聚集索引一样,只存被索引列的值,而二级索引的叶子页除了索引列值,还存这一列对应的主键值。
七、InnoDB 和 MyISAM 的数据分布对比
以下表为例,我们看下 InnoDB 和 MyISAM 是如何存储这个表的:
create table layout_test(
col1 int(11) primary key,
col2 int(11) not null,
key(col2)
);
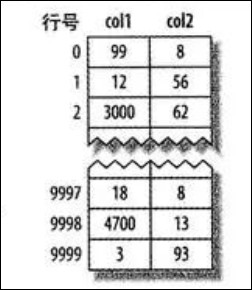
MyISAM 表 layout_test 的数据分布如下:
InnoDB 表的数据分布,聚集索引(主键索引)分布如下:
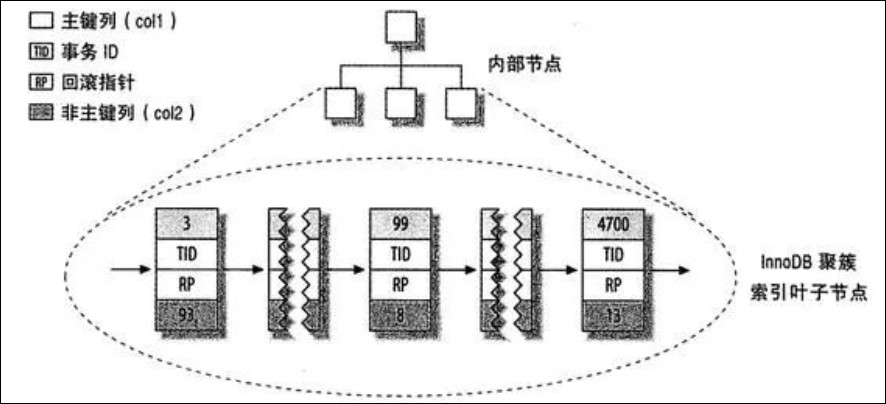
可以看到,叶子节点存储了整个表的数据,而不是只有索引列,每个叶子节点包含了主键值、事务ID、用于事务和 MVCC 的回滚指针以及所有的剩余列(col2)。
二级索引分布如下:
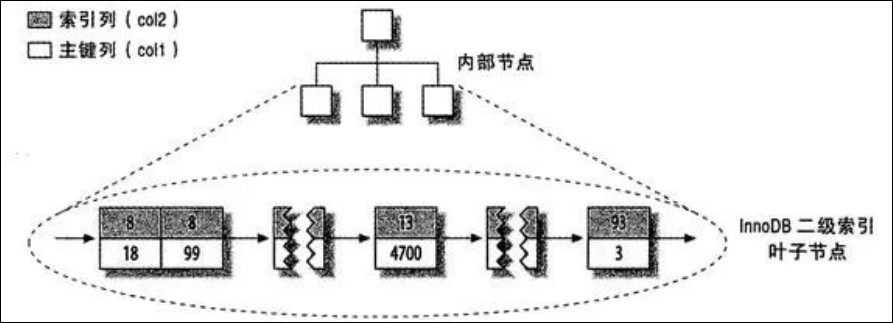
二级索引的叶子节点中存储的不是“行指针”,而是主键值,并以此作为指向行的“指针”。这样的策略减少了当出现行移动或者数据页分裂时二级索引的维护工作。使用主键当做指针会让二级索引占更多空间,但好处是 InnoDB 在移动行时无需更新二级索引中的这个指针。
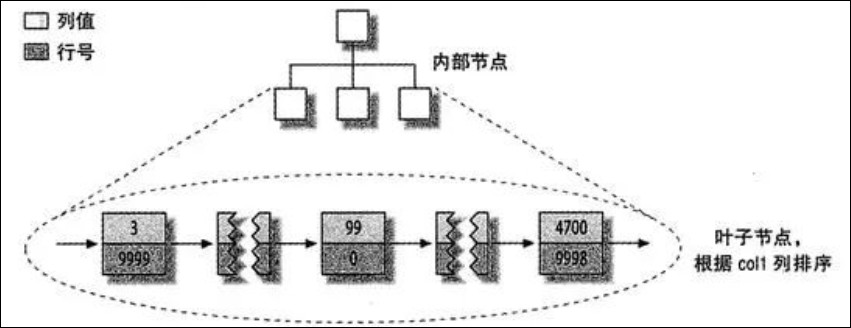
MyISAM 表的数据分布
col1 列上的索引:
col2 列上的索引:
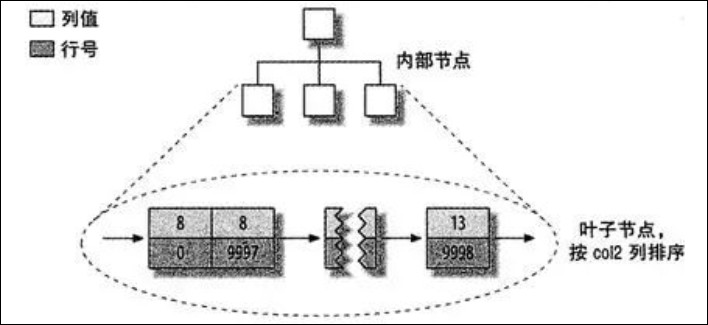
实际上 MyISAM 中主键索引和其他索引在结构上没有什么不同。
从下图可以看出 InnoDB 和 MyISAM 保存数据和索引的区别。
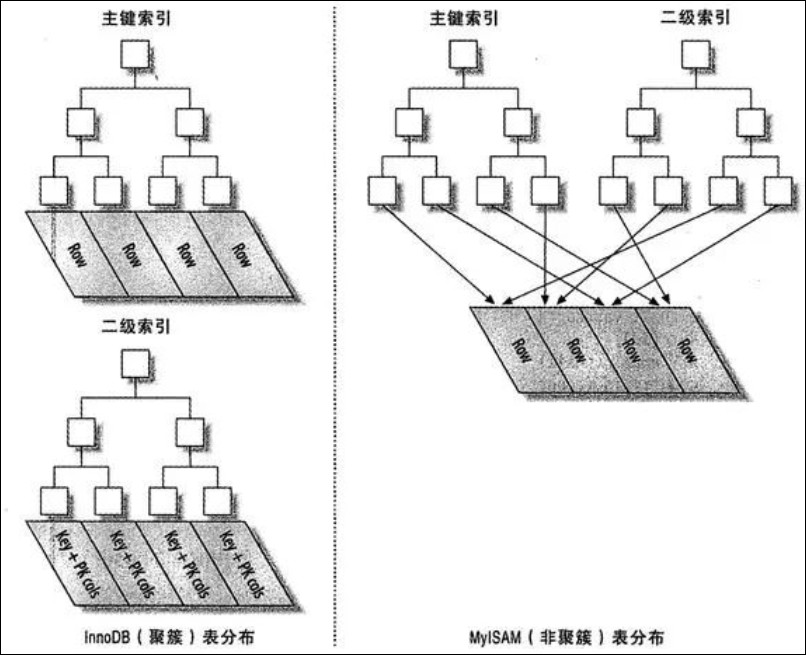
聚集索引的优点:
可以把相关数据保存在一起,例如实现电子邮箱时,根据用户 ID 来聚集数据,读取少数的数据页就能获取某个用户的全部邮件。
聚集索引将索引和数据保存在同一个 B 树中,因此从聚集索引中获取数据比在非聚集索引中要快一些。
聚集索引的缺点:
插入速度严重依赖插入顺序。按照主键的顺序插入是加载数据到 InnoDB 表中速度最快的方式。假如磁盘中的某一个已经存满了,但是新增的行要插入到这一页当中,存储引擎就会把该页分裂成两个页面来容纳该行,这就是一次页分裂操作。页分裂会导致表占用更多的磁盘空间。
更新聚集索引列的代较很高,会强制 InnoDB 将每个被更新的行移动到新的位置。
用二级索引访问数据需要两个索引查找,不是一次。因为要先从二级索引的叶子节点获得主键值,再根据这主键去聚集索引中查到对应的行,所以需要两次 B 树查找。
顺序主键策略:
在 InnoDB 表中使用自增主键是既简单性能又高的策略,这样可以保证数据按顺序写入。
最好避免随机的聚集索引,从性能的角度考虑,使用 UUID 来作为聚集索引是很糟糕的,这样不仅插入行花费的时间长,而且索引占用的空间也更大。